Textual Equilibrium Propagation for Deep Compound AI Systems
作者: Minghui Chen, Wenlong Deng, James Zou, Han Yu, Xiaoxiao Li
分类: cs.LG, cs.AI
发布日期: 2026-04-06
💡 一句话要点
提出文本均衡传播(TEP)以解决深度复合AI系统中长程文本反馈的梯度消失/爆炸问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本均衡传播 深度复合AI系统 长时程任务 梯度消失 梯度爆炸 局部学习 大型语言模型
📋 核心要点
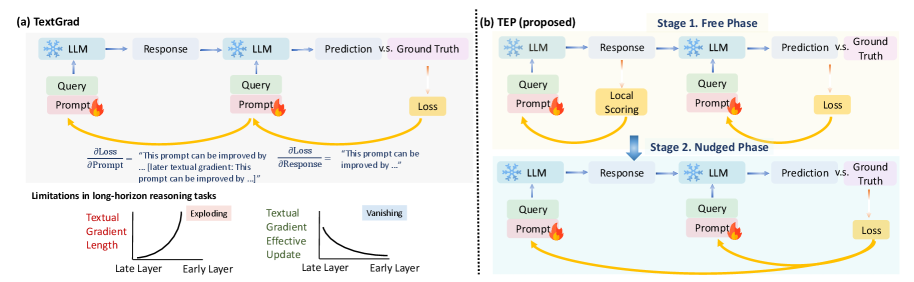
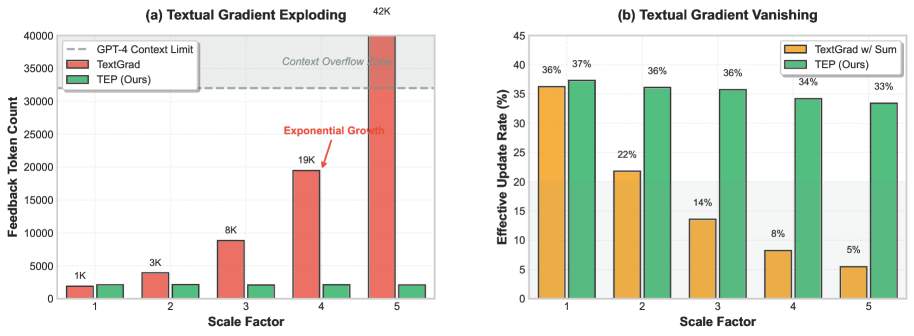
- 现有基于全局文本反馈传播的方法在深度复合AI系统中存在梯度爆炸和消失问题,导致性能下降。
- 论文提出文本均衡传播(TEP),一种受能量模型启发的局部学习原则,通过局部优化和受控适应来缓解这些问题。
- 实验表明,TEP在长时程QA和多agent工具使用任务上优于全局传播方法,且增益随深度增加。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被部署为复合AI系统的一部分,这些系统在长时程工作流程中协调多个模块(例如,检索器、工具、验证器)。最近的全局传播文本反馈方法(例如TextGrad)使得优化此类管道成为可能,但我们发现性能会随着系统深度的增加而降低。特别是,长时程agentic工作流程表现出两种深度缩放失效模式:1)文本梯度爆炸,其中文本反馈随深度呈指数增长,导致消息过长并放大评估偏差;2)文本梯度消失,其中有限的长上下文能力导致模型过度强调部分反馈,并且冗长反馈的压缩导致下游消息随着向上游传播而逐渐失去特异性。为了缓解这些问题,我们引入了文本均衡传播(TEP),这是一种受能量模型中均衡传播启发的局部学习原则。TEP包括两个阶段:1)自由阶段,其中局部LLM评论员迭代地细化提示,直到达到平衡(不再建议进一步改进);2)nudged阶段,使用通过前向信号而不是后向反馈链传播的任务级目标,应用具有有界修改强度的近端提示编辑。这种设计支持局部提示优化,然后是朝着全局目标的受控适应,而没有全局文本反向传播的计算负担和信号退化。在长时程QA基准和多agent工具使用数据集上,TEP始终优于全局传播方法(如TextGrad),提高了准确性和效率。增益随着深度的增加而增长,同时保持了深度复合AI系统中黑盒LLM组件的实用性。
🔬 方法详解
问题定义:现有的深度复合AI系统,特别是那些依赖于长时程工作流程的系统,在利用大型语言模型(LLMs)进行全局文本反馈传播时,面临着梯度爆炸和梯度消失的问题。梯度爆炸导致反馈信息过长,评估偏差放大;梯度消失则导致模型过度关注局部反馈,长程信息丢失,最终影响系统性能。
核心思路:论文的核心思路是借鉴能量模型中的均衡传播思想,提出一种局部学习原则——文本均衡传播(TEP)。TEP旨在通过局部LLM评论员的迭代优化,以及受控的全局目标适应,避免全局反向传播带来的梯度问题,从而提高深度复合AI系统的性能和效率。
技术框架:TEP包含两个主要阶段:自由阶段(Free Phase)和 nudged 阶段。在自由阶段,局部LLM评论员迭代地细化提示,直到达到平衡状态,即不再提出改进建议。在 nudged 阶段,利用任务级别的目标,通过前向信号传播,对提示进行受控的修改,实现对全局目标的适应。整个框架避免了全局反向传播,从而减轻了梯度爆炸和消失的问题。
关键创新:TEP的关键创新在于将能量模型中的均衡传播思想应用于文本反馈的优化。与传统的全局反向传播方法不同,TEP采用局部优化和受控适应的策略,避免了长链反馈带来的梯度问题。此外,TEP的设计允许使用黑盒LLM组件,增强了系统的实用性。
关键设计:TEP的关键设计包括:1) 局部LLM评论员的迭代优化过程,通过迭代细化提示,达到局部平衡;2) nudged 阶段中,对提示的修改强度进行控制,避免过度调整;3) 使用前向信号传播任务级别目标,而不是后向反馈链,从而避免梯度问题。具体的参数设置和损失函数可能需要根据具体的应用场景进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TEP在长时程QA和多agent工具使用数据集上,显著优于全局传播方法(如TextGrad)。具体而言,TEP在准确性和效率方面均有提升,且增益随着系统深度的增加而增长。这些结果验证了TEP在解决深度复合AI系统中梯度问题方面的有效性。
🎯 应用场景
TEP可应用于各种需要深度复合AI系统的场景,例如智能客服、自动化报告生成、多智能体协作等。通过提高长时程任务的性能和效率,TEP能够提升这些应用的智能化水平和用户体验,并降低计算成本。未来,TEP有望成为构建更复杂、更强大的AI系统的关键技术。
📄 摘要(原文)
Large language models (LLMs) are increasingly deployed as part of compound AI systems that coordinate multiple modules (e.g., retrievers, tools, verifiers) over long-horizon workflows. Recent approaches that propagate textual feedback globally (e.g., TextGrad) make it feasible to optimize such pipelines, but we find that performance degrades as system depth grows. In particular, long-horizon agentic workflows exhibit two depth-scaling failure modes: 1) exploding textual gradient, where textual feedback grows exponentially with depth, leading to prohibitively long message and amplifies evaluation biases; and 2) vanishing textual gradient, where limited long-context ability causes models overemphasize partial feedback and compression of lengthy feedback causes downstream messages to lose specificity gradually as they propagate many hops upstream. To mitigate these issues, we introduce Textual Equilibrium Propagation (TEP), a local learning principle inspired by Equilibrium Propagation in energy-based models. TEP includes two phases: 1) a free phase where a local LLM critics iteratively refine prompts until reaching equilibrium (no further improvements are suggested); and 2) a nudged phase which applies proximal prompt edits with bounded modification intensity, using task-level objectives that propagate via forward signaling rather than backward feedback chains. This design supports local prompt optimization followed by controlled adaptation toward global goals without the computational burden and signal degradation of global textual backpropagation. Across long-horizon QA benchmarks and multi-agent tool-use dataset, TEP consistently improves accuracy and efficiency over global propagation methods such as TextGrad. The gains grows with depth, while preserving the practicality of black-box LLM components in deep compound AI system.