Seer: Online Context Learning for Fast Synchronous LLM Reinforcement Learning
作者: Ruoyu Qin, Weiran He, Weixiao Huang, Yangkun Zhang, Yikai Zhao, Bo Pang, Xinran Xu, Yingdi Shan, Yongwei Wu, Mingxing Zhang
分类: cs.DC, cs.LG
发布日期: 2026-04-06
💡 一句话要点
Seer:面向快速同步LLM强化学习的在线上下文学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 上下文学习 长尾延迟 负载均衡
📋 核心要点
- 现有同步RL系统在LLM强化学习中存在rollout阶段的长尾延迟和资源利用率低下的问题。
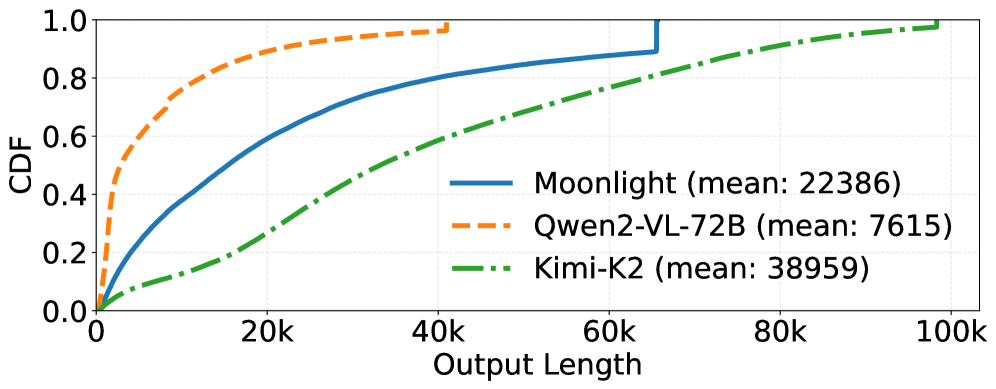
- Seer通过观察到共享相同prompt的请求具有相似的输出特征,利用上下文学习来优化rollout过程。
- Seer通过分割rollout、上下文感知调度和自适应分组推测解码,实现了显著的吞吐量提升和延迟降低。
📝 摘要(中文)
强化学习(RL)已成为推动现代大型语言模型(LLM)发展的关键技术,但现有的同步RL系统面临严重的性能瓶颈。Rollout阶段占据端到端迭代时间的大部分,由于固有的工作负载不平衡,遭受显著的长尾延迟和较差的资源利用率。我们提出了Seer,一种新颖的上下文学习RL系统,通过一个关键观察来解决这些挑战:共享相同prompt的请求在输出长度和响应模式上表现出很强的相似性。利用这一洞察,Seer引入了三种协调技术:(1)用于动态负载平衡的分割rollout,(2)用于缓解长尾请求延迟的上下文感知调度,以及(3)用于加速生成的自适应分组推测解码。这些机制协同工作,显著减少rollout期间的长尾延迟并提高资源效率。在生产级RL工作负载上的评估表明,与最先进的同步RL系统相比,Seer实现了高达2.04倍的端到端rollout吞吐量提升,同时显著降低了72-94%的长尾延迟。
🔬 方法详解
问题定义:论文旨在解决同步强化学习系统中,由于rollout阶段固有的工作负载不平衡,导致的长尾延迟和资源利用率低下的问题。现有方法难以有效处理不同请求之间的差异,导致整体效率受限于最慢的请求。
核心思路:论文的核心思路是利用上下文学习,即观察到具有相似prompt的请求在输出长度和响应模式上具有相似性。通过预测请求的特征,可以更好地进行负载均衡和调度,从而减少长尾延迟并提高资源利用率。
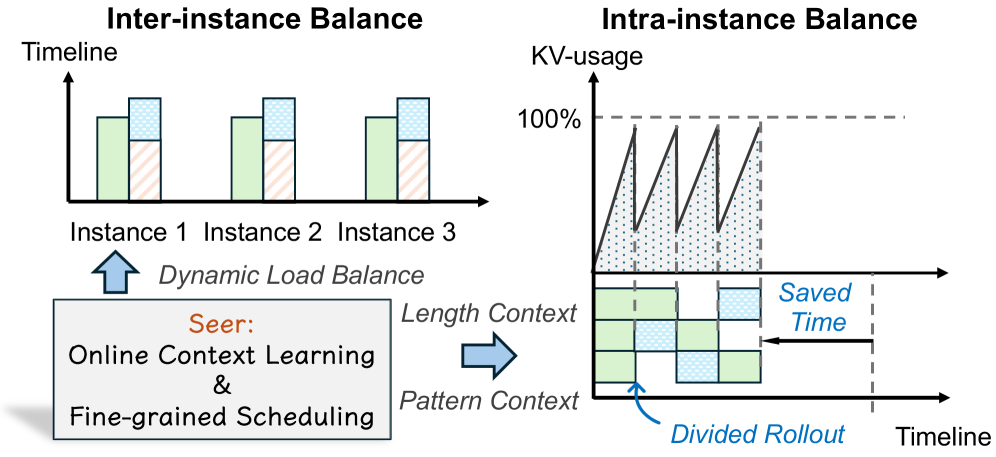
技术框架:Seer系统的整体框架包含三个主要模块:分割rollout、上下文感知调度和自适应分组推测解码。分割rollout将请求动态分配到不同的worker,以实现负载均衡。上下文感知调度根据请求的上下文信息(例如prompt)预测其完成时间,并优先调度预计完成时间较短的请求。自适应分组推测解码则通过将相似的请求分组,并利用推测解码加速生成过程。
关键创新:Seer的关键创新在于将上下文学习引入到同步强化学习系统中,并设计了相应的分割rollout、上下文感知调度和自适应分组推测解码机制。与现有方法相比,Seer能够更有效地利用资源,减少长尾延迟,并提高整体吞吐量。
关键设计:分割rollout采用动态分配策略,根据worker的负载情况和请求的预测完成时间进行分配。上下文感知调度使用一个轻量级的模型来预测请求的完成时间,并根据预测结果进行优先级排序。自适应分组推测解码则根据请求的相似度进行分组,并使用共享的上下文信息进行推测解码。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Seer在生产级RL工作负载上实现了高达2.04倍的端到端rollout吞吐量提升,同时显著降低了72-94%的长尾延迟。这些结果表明Seer能够显著提高同步RL系统的效率和性能,使其更适用于大规模LLM的训练。
🎯 应用场景
Seer可应用于各种需要大规模LLM强化学习的场景,例如对话系统、文本生成、代码生成等。通过提高rollout效率,Seer可以加速LLM的训练过程,降低训练成本,并提升LLM的性能。该研究对于推动LLM在实际应用中的普及具有重要意义。
📄 摘要(原文)
Reinforcement Learning (RL) has emerged as a critical technique for advancing modern Large Language Models (LLMs), yet existing synchronous RL systems face severe performance bottlenecks. The rollout phase, which dominates end-to-end iteration time, suffers from substantial long-tail latency and poor resource utilization due to inherent workload imbalance. We present Seer, a novel context learning RL system that addresses these challenges through a key observation: requests sharing the same prompt exhibit strong similarities in output lengths and response patterns. Leveraging this insight, Seer introduces three coordinated techniques: (1) divided rollout for dynamic load balancing, (2) context-aware scheduling to mitigate long-tail request delays, and (3) adaptive grouped speculative decoding to accelerate generation. These mechanisms work in concert to markedly reduce long-tail latency and improve resource efficiency during rollout. Evaluations on production-grade RL workloads demonstrate that Seer achieves up to 2.04$\times$ end-to-end rollout throughput improvement compared to the state-of-the-art synchronous RL systems, while notably reducing long-tail latency by 72-94%.