Diffusion Models as Dataset Distillation Priors
作者: Duo Su, Huyu Wu, Huanran Chen, Yiming Shi, Yuzhu Wang, Xi Ye, Jun Zhu
分类: cs.LG
发布日期: 2026-04-06
💡 一句话要点
提出DAP:利用扩散模型先验提升数据集蒸馏的代表性,无需额外训练。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据集蒸馏 扩散模型 代表性学习 生成模型 模型泛化
📋 核心要点
- 现有数据集蒸馏方法忽略了扩散模型中固有的代表性先验,导致需要额外的约束来保证数据质量。
- DAP方法通过Mercer核量化特征空间中合成数据和真实数据的相似性,形式化了代表性先验。
- 实验表明,DAP在ImageNet-1K等数据集上优于现有方法,并实现了更好的跨架构泛化能力。
📝 摘要(中文)
数据集蒸馏旨在从大型数据集中合成紧凑而信息丰富的子集。该领域的一个重要挑战是在单个蒸馏数据集中实现多样性、泛化性和代表性的统一。尽管最近的生成式数据集蒸馏方法采用强大的扩散模型作为基础模型,但扩散模型中固有的代表性先验却被忽视了。因此,这些方法通常需要集成外部约束来提高数据质量。为了解决这个问题,我们提出了Diffusion As Priors (DAP),它通过使用Mercer核量化特征空间中合成数据和真实数据之间的相似性来形式化代表性。然后,我们将此先验作为指导来引导反向扩散过程,从而增强蒸馏样本的代表性,而无需任何重新训练。在ImageNet-1K及其子集等大型数据集上的大量实验表明,DAP在生成高保真数据集方面优于最先进的方法,同时实现了卓越的跨架构泛化。我们的工作不仅建立了扩散先验与数据集蒸馏目标之间的理论联系,而且还提供了一个实用的、无需训练的框架,用于提高蒸馏数据集的质量。
🔬 方法详解
问题定义:数据集蒸馏旨在从大规模数据集中提取一个小的、具有代表性的子集,用于训练模型,以达到与使用完整数据集训练相似的性能。现有的方法,特别是基于扩散模型的方法,虽然在生成高质量样本方面表现出色,但往往忽略了扩散模型本身所蕴含的关于数据分布的先验知识,导致生成的蒸馏数据集可能缺乏代表性,需要额外的约束或正则化来提升性能。
核心思路:DAP的核心思路是显式地利用扩散模型中蕴含的代表性先验知识,指导数据集蒸馏过程。具体来说,DAP通过量化合成数据和真实数据在特征空间中的相似性来形式化代表性,并将其作为一种先验信息,引导反向扩散过程,从而生成更具代表性的蒸馏样本。这样做的目的是在不进行额外训练的情况下,提升蒸馏数据集的质量和泛化能力。
技术框架:DAP方法主要包含以下几个阶段:1. 使用扩散模型生成初始的合成数据集。2. 使用预训练的特征提取器(例如,ImageNet上预训练的ResNet)提取合成数据和真实数据的特征。3. 使用Mercer核函数(例如,高斯核)计算合成数据和真实数据在特征空间中的相似度,得到一个相似度矩阵。4. 将该相似度矩阵作为先验信息,指导反向扩散过程,从而生成更接近真实数据分布的蒸馏样本。这个过程不需要重新训练扩散模型。
关键创新:DAP的关键创新在于将扩散模型中的代表性先验显式地提取出来,并将其用于指导数据集蒸馏过程。与现有方法相比,DAP不需要额外的训练或正则化,就可以生成更具代表性的蒸馏数据集,从而提升模型的泛化能力。此外,DAP还提供了一个理论框架,将扩散先验与数据集蒸馏的目标联系起来。
关键设计:DAP的关键设计包括:1. 使用预训练的深度学习模型提取特征,以获得更具语义信息的特征表示。2. 使用Mercer核函数来量化特征空间中的相似度,这使得DAP可以处理高维特征,并捕捉数据之间的非线性关系。3. 将相似度矩阵作为一种引导信号,注入到反向扩散过程中,从而控制生成样本的分布。具体实现上,可以通过调整反向扩散过程中的噪声水平或梯度方向来实现。
🖼️ 关键图片

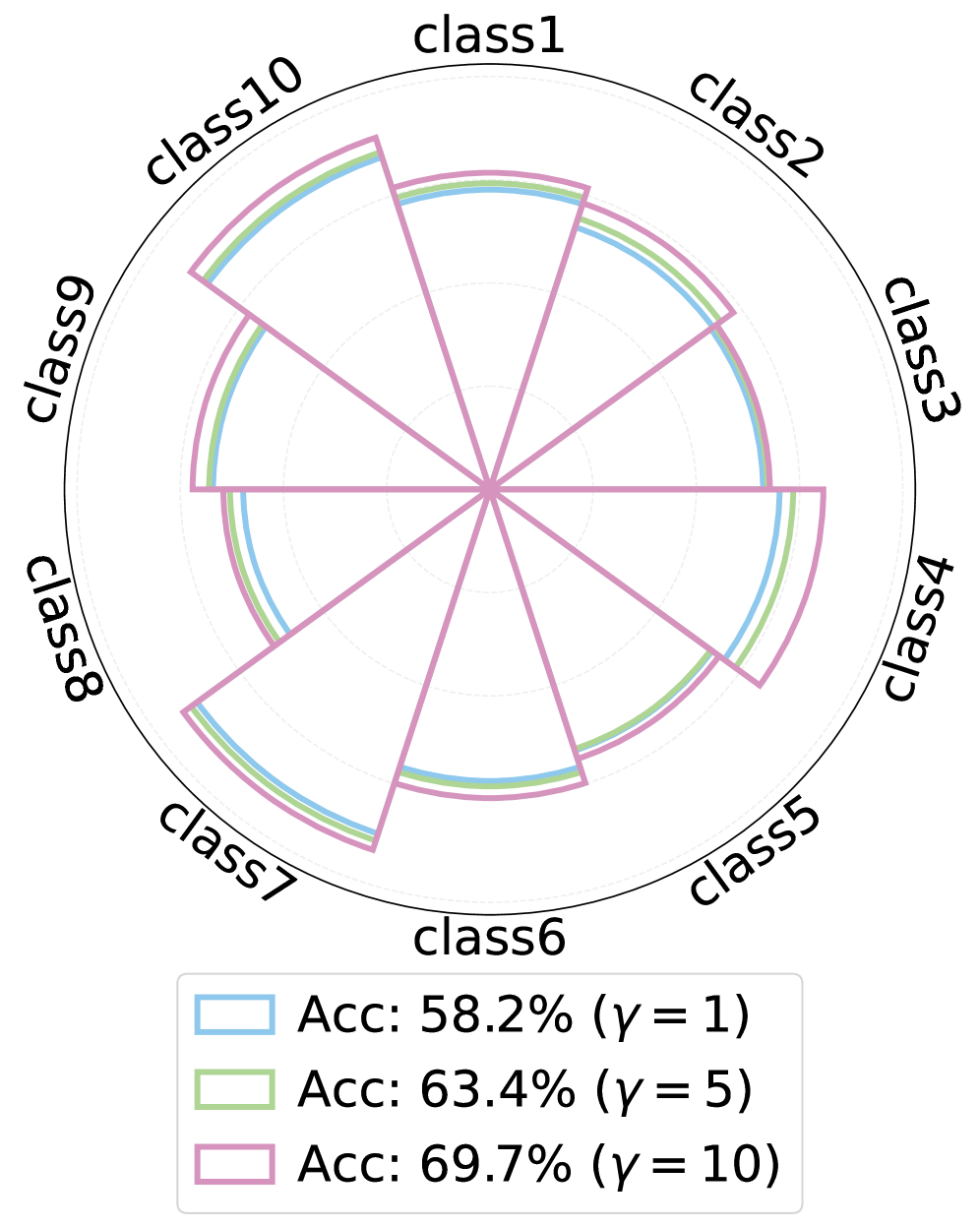
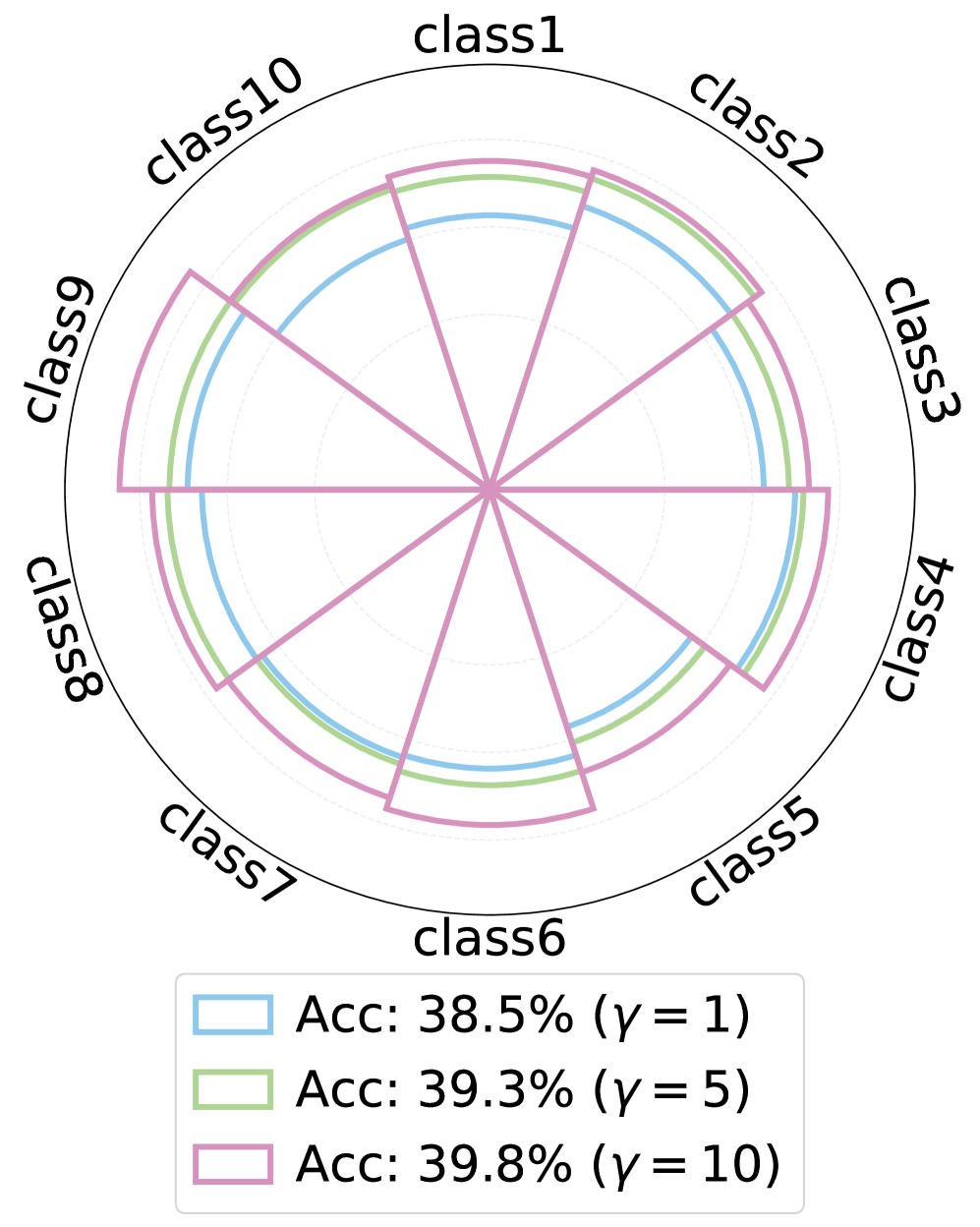
📊 实验亮点
DAP在ImageNet-1K及其子集上进行了广泛的实验,结果表明DAP在生成高保真数据集方面优于最先进的方法。例如,在某些设置下,使用DAP生成的蒸馏数据集训练的模型,其性能比使用其他方法生成的蒸馏数据集训练的模型高出几个百分点。此外,DAP还表现出卓越的跨架构泛化能力,即使用DAP生成的蒸馏数据集训练的模型,在不同的网络架构上都能保持较高的性能。
🎯 应用场景
DAP方法在数据压缩、模型加速和隐私保护等领域具有广泛的应用前景。例如,在资源受限的边缘设备上,可以使用DAP生成一个小的、具有代表性的数据集,用于训练轻量级模型,从而实现高效的推理。此外,DAP还可以用于生成具有隐私保护特性的合成数据,用于训练模型,而无需访问原始敏感数据。
📄 摘要(原文)
Dataset distillation aims to synthesize compact yet informative datasets from large ones. A significant challenge in this field is achieving a trifecta of diversity, generalization, and representativeness in a single distilled dataset. Although recent generative dataset distillation methods adopt powerful diffusion models as their foundation models, the inherent representativeness prior in diffusion models is overlooked. Consequently, these approaches often necessitate the integration of external constraints to enhance data quality. To address this, we propose Diffusion As Priors (DAP), which formalizes representativeness by quantifying the similarity between synthetic and real data in feature space using a Mercer kernel. We then introduce this prior as guidance to steer the reverse diffusion process, enhancing the representativeness of distilled samples without any retraining. Extensive experiments on large-scale datasets, such as ImageNet-1K and its subsets, demonstrate that DAP outperforms state-of-the-art methods in generating high-fidelity datasets while achieving superior cross-architecture generalization. Our work not only establishes a theoretical connection between diffusion priors and the objectives of dataset distillation but also provides a practical, training-free framework for improving the quality of the distilled dataset.