Local Reinforcement Learning with Action-Conditioned Root Mean Squared Q-Functions
作者: Frank Wu, Mengye Ren
分类: cs.LG, cs.AI
发布日期: 2026-04-06
💡 一句话要点
提出基于动作条件均方根Q函数的局部强化学习方法,提升无反向传播RL算法性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 局部强化学习 无反向传播 Forward-Forward算法 Q函数 时序差分学习
📋 核心要点
- Forward-Forward算法在监督学习中表现出色,但在强化学习领域仍有空白,缺乏有效的局部学习方法。
- 论文提出动作条件均方根Q函数(ARQ),利用优良性函数和动作条件进行局部强化学习,无需反向传播。
- 实验表明,ARQ在MinAtar和DeepMind Control Suite上超越现有局部RL算法,甚至优于部分反向传播算法。
📝 摘要(中文)
本文提出了一种新的价值估计方法,即动作条件均方根Q函数(ARQ),它利用一个优良性函数和动作条件进行局部强化学习,并使用时序差分学习。该方法受到Forward-Forward算法的启发,后者使用层活动统计作为优良性函数。尽管ARQ方法简单且具有生物学基础,但在MinAtar和DeepMind Control Suite基准测试中,其性能优于最先进的无反向传播的局部强化学习方法,并且在大多数任务上也优于使用反向传播训练的算法。代码可在[this https URL]找到。
🔬 方法详解
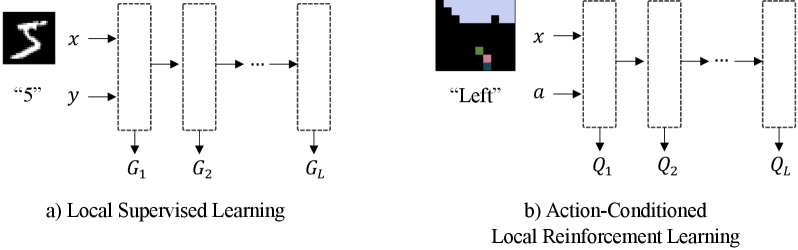
问题定义:现有的强化学习方法通常依赖反向传播算法进行梯度更新,这在生物学上缺乏合理性,并且计算成本较高。Forward-Forward算法虽然避免了反向传播,但主要应用于监督学习,在强化学习领域的应用有限。因此,需要一种无需反向传播且适用于强化学习的局部学习方法。
核心思路:论文的核心思路是借鉴Forward-Forward算法中利用层活动统计作为优良性函数的思想,并将其扩展到强化学习领域。通过引入动作条件,构建动作条件均方根Q函数(ARQ),从而实现对Q值的局部估计。这种方法旨在利用局部信息进行学习,避免全局反向传播。
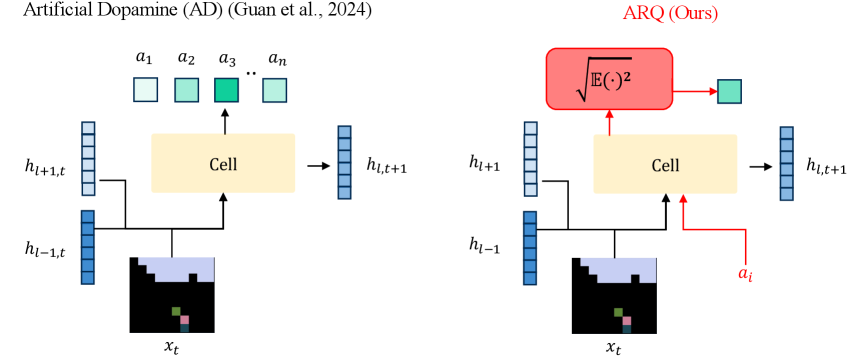
技术框架:ARQ方法主要包含以下几个阶段:1) 使用神经网络提取状态特征;2) 根据当前状态和动作,计算动作条件均方根Q值;3) 使用时序差分(TD)学习更新Q值函数。整体框架类似于传统的Q-learning,但关键区别在于Q值的估计方式,ARQ使用基于优良性函数的局部计算,而非反向传播。
关键创新:最重要的创新点在于提出了动作条件均方根Q函数(ARQ),它将Forward-Forward算法的优良性函数思想引入强化学习,并结合动作条件,实现了无需反向传播的局部Q值估计。与传统的Q-learning相比,ARQ避免了全局梯度计算,更具生物学合理性,并且可能更易于并行化。
关键设计:ARQ的关键设计包括:1) 优良性函数的选择,论文可能采用了某种形式的层活动统计作为优良性函数;2) 动作条件的具体实现方式,例如将动作嵌入到状态特征中;3) 时序差分学习的更新规则,可能采用了某种形式的TD(λ)算法;4) 网络结构的设计,例如使用卷积神经网络提取图像特征。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ARQ方法在MinAtar和DeepMind Control Suite基准测试中,性能优于现有的无反向传播局部强化学习方法。更重要的是,在大多数任务上,ARQ甚至超越了使用反向传播训练的算法,这表明局部学习方法在某些情况下可以达到甚至超过全局优化方法的效果。具体的性能提升幅度未知,需要参考论文中的详细数据。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、自动驾驶等领域,尤其是在计算资源受限或需要生物学合理性的场景下。ARQ方法有望推动局部强化学习的发展,并为设计更高效、更具适应性的智能体提供新的思路。此外,该方法也可能启发新的神经网络架构和学习算法。
📄 摘要(原文)
The Forward-Forward (FF) Algorithm is a recently proposed learning procedure for neural networks that employs two forward passes instead of the traditional forward and backward passes used in backpropagation. However, FF remains largely confined to supervised settings, leaving a gap at domains where learning signals can be yielded more naturally such as RL. In this work, inspired by FF's goodness function using layer activity statistics, we introduce Action-conditioned Root mean squared Q-Functions (ARQ), a novel value estimation method that applies a goodness function and action conditioning for local RL using temporal difference learning. Despite its simplicity and biological grounding, our approach achieves superior performance compared to state-of-the-art local backprop-free RL methods in the MinAtar and the DeepMind Control Suite benchmarks, while also outperforming algorithms trained with backpropagation on most tasks. Code can be found atthis https URL.