DRtool: An Interactive Tool for Analyzing High-Dimensional Clusterings
作者: Justin Lin, Julia Fukuyama
分类: stat.AP, cs.LG
发布日期: 2026-04-06
💡 一句话要点
DRtool:用于分析高维聚类结果的交互式工具,辅助识别伪聚类。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 高维数据聚类 非线性降维 交互式可视化 伪聚类识别 数据分析工具
📋 核心要点
- 高维数据聚类后,非线性降维可视化易产生伪聚类,导致过度解读。
- DRtool通过交互式分析,从全局和局部多角度评估聚类结果的真实性。
- DRtool提供多种分析图,帮助用户区分真实聚类和降维引入的虚假结构。
📝 摘要(中文)
面对新的数据,我们通常进行聚类分析,以更好地理解数据的结构和数据中存在的典型样本。这个过程通常包括数据的可视化,作为发现或验证聚类的一种方式。然而,数据复杂性和维度的增加使得这一步非常棘手。为了可视化数据,非线性降维方法是事实上的标准,因为它们能够非均匀地拉伸和收缩空间,从而保持局部聚类。然而,由于这个过程需要对空间进行剧烈的操作,非线性降维方法已知会产生虚假的结构,尤其是在处理不当的情况下。一个常见的后果是数据的过度聚类,这往往不会被未经训练的人员发现。为了应对这种现象,我们开发了一个交互式工具,使分析人员能够区分虚假聚类,并更好地解释他们的高维聚类结果。该工具使用各种分析图,从多个角度提供关于数据的全局结构以及局部聚类间关系的信息,帮助用户确定他们的高维聚类结果的合理性。该工具可以通过名为DRtool的R包获得。
🔬 方法详解
问题定义:高维数据聚类后,为了便于理解和验证聚类结果,通常会使用非线性降维方法进行可视化。然而,非线性降维方法在降维过程中会对空间进行扭曲,容易产生虚假的聚类结构,导致分析人员过度解读聚类结果。现有方法缺乏有效的工具来区分真实的聚类结构和降维引入的伪聚类。
核心思路:DRtool的核心思路是通过提供一个交互式的分析环境,使用户能够从多个角度审视聚类结果。它利用多种分析图表,既关注数据的全局结构,又关注局部聚类之间的关系,从而帮助用户判断聚类结果的合理性,并区分真实聚类和伪聚类。
技术框架:DRtool是一个R包,提供了一系列交互式可视化工具。其整体框架包含以下几个主要模块: 1. 全局结构分析:提供诸如主成分分析(PCA)等方法的可视化结果,帮助用户了解数据的整体分布。 2. 局部聚类关系分析:提供聚类间的距离、相似度等信息的可视化,帮助用户理解聚类之间的关系。 3. 交互式探索:允许用户通过交互操作,例如选择特定的聚类或样本,来深入分析数据。
关键创新:DRtool的关键创新在于其交互性和多角度分析。它不是简单地提供一种可视化方法,而是提供一个完整的分析流程,使用户能够主动地探索数据,并根据多个指标来判断聚类结果的合理性。与传统的静态可视化方法相比,DRtool能够更好地帮助用户发现潜在的问题,并避免过度解读聚类结果。
关键设计:DRtool的关键设计包括: 1. 多种分析图表:根据不同的分析目的,提供不同的图表类型,例如散点图、箱线图、热图等。 2. 交互式操作:允许用户通过鼠标点击、拖拽等操作,选择特定的数据子集进行分析。 3. R包实现:使用R语言实现,方便用户集成到现有的数据分析流程中。
🖼️ 关键图片
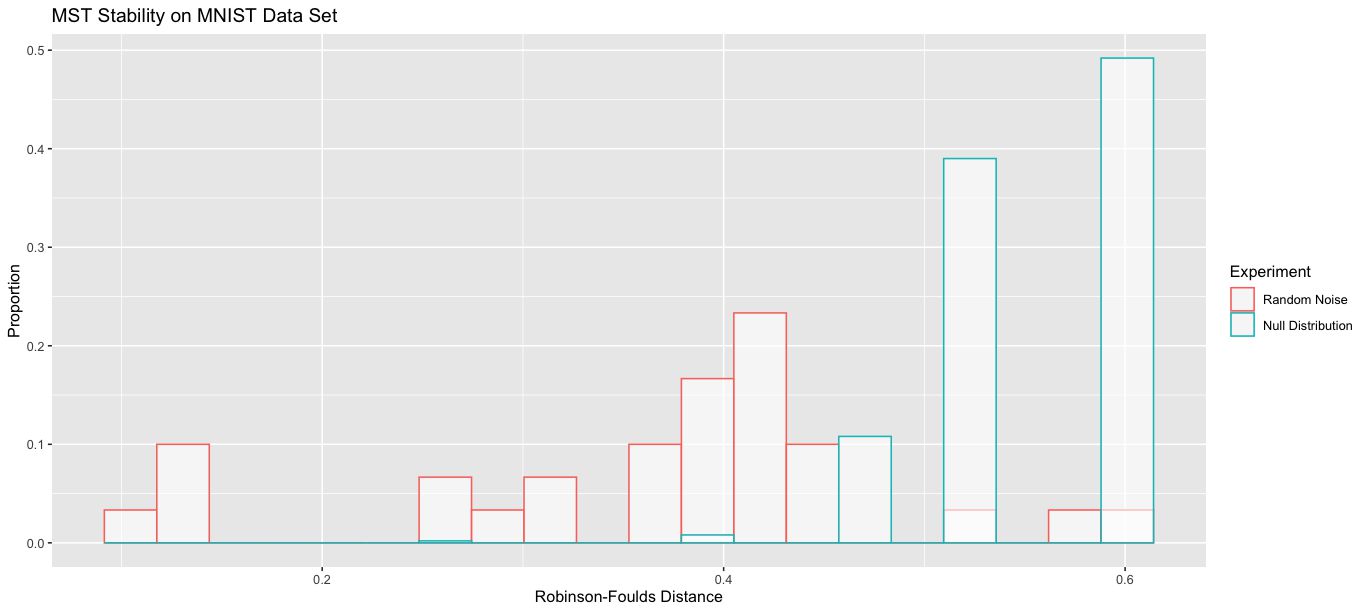
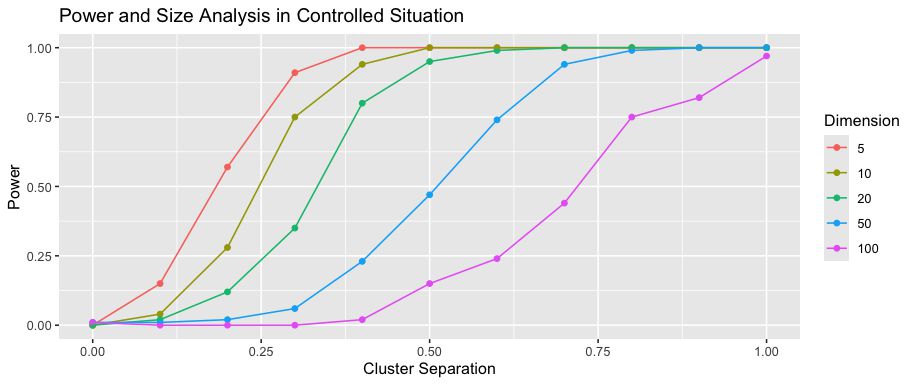

📊 实验亮点
论文主要贡献在于工具的设计和实现,并没有提供具体的性能数据或对比基线。其亮点在于提供了一种交互式分析高维聚类结果的有效方法,能够帮助用户识别伪聚类,从而提高聚类分析的可靠性。
🎯 应用场景
DRtool可广泛应用于生物信息学、金融分析、市场营销等领域,帮助研究人员和分析师更好地理解高维数据的聚类结构。通过避免对虚假聚类的错误解读,该工具可以提高数据分析的准确性和可靠性,从而支持更明智的决策。
📄 摘要(原文)
When faced with new data, we often conduct a cluster analysis to obtain a better understanding of the data's structure and the archetypical samples present in the data. This process often includes visualization of the data, either as a way to discover or verify clusters. However, the increases in data complexity and dimensionality has made this step very tricky. To visualize data, nonlinear dimension reduction methods are the de facto standard for their ability to non-uniformly stretch and shrink space in order to preserve local clusters. Because this process requires a drastic manipulation of space, however, nonlinear dimension reduction methods are known to produce false structures, especially when mishandled. A common consequence that often goes undetected by the untrained eye is over-clustering of the data. In efforts to deal with this phenomenon, we developed an interactive tool that empowers analysts to distinguish false clusters and better interpret their high-dimensional clustering results. The tool uses various analytical plots to provide a multi-faceted perspective on the data's global structure as well as local inter-cluster relationships, helping users determine the legitimacy of their high-dimensional clustering results. The tool is available via an R package named DRtool.