Accelerated Learning with Linear Temporal Logic using Differentiable Simulation
作者: Alper Kamil Bozkurt, Calin Belta, Ming C. Lin
分类: cs.LG, cs.RO
发布日期: 2026-04-06
💡 一句话要点
提出基于可微仿真的线性时序逻辑加速学习框架,解决强化学习中安全约束问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 线性时序逻辑 强化学习 可微仿真 形式化方法 安全约束 奖励塑造 Büchi自动机
📋 核心要点
- 现有强化学习方法难以在实际环境中保证安全性和可靠性约束,且形式化规范语言的奖励通常稀疏。
- 该方法通过可微仿真和软标签松弛离散自动机转换,生成可微奖励和状态表示,缓解了奖励稀疏性问题。
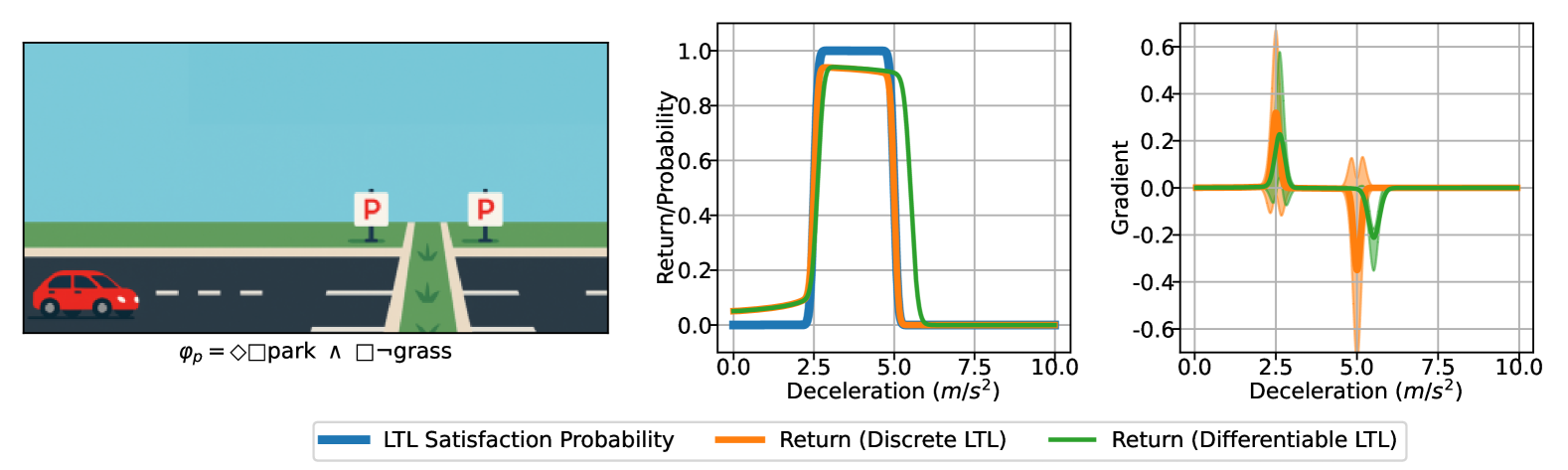
- 实验表明,该方法在复杂连续控制任务中显著加速训练,并实现了高达两倍于离散基线的收益。
📝 摘要(中文)
本文提出了一种端到端框架,将线性时序逻辑(LTL)与可微仿真相结合,从而能够直接从形式化规范中进行高效的基于梯度的学习。该方法通过状态的软标签来松弛离散自动机的转换,产生可微的奖励和状态表示,从而缓解了LTL固有的稀疏性问题,同时保持了目标健全性。论文提供了理论保证,将Büchi接受与离散和可微LTL回报联系起来,并推导了确定性和随机环境中差异的可调边界。在复杂的、非线性的、富含接触的连续控制任务中,该方法显著加速了训练,并实现了高达两倍于离散基线的收益。此外,该方法还展示了与奖励机器的兼容性,从而无需修改即可覆盖co-safe LTL和LTL$_ ext{f}$。通过使基于自动机的奖励可微,该工作桥接了形式化方法和深度强化学习,从而能够在连续域中实现安全、规范驱动的学习。
🔬 方法详解
问题定义:强化学习在实际应用中,需要满足安全性和可靠性约束。传统的基于状态避免和约束马尔可夫决策过程的方法,难以捕捉轨迹层面的需求,或者导致过于保守的行为。线性时序逻辑(LTL)虽然可以提供正确的构造目标,但其奖励通常是稀疏的,启发式的奖励塑造可能会破坏正确性。因此,如何高效地利用LTL规范来指导强化学习,同时克服奖励稀疏性问题,是一个重要的挑战。
核心思路:论文的核心思路是将LTL规范与可微仿真环境相结合,通过可微的方式来计算LTL的奖励,从而能够利用梯度信息来加速强化学习的训练过程。通过将离散的自动机转换进行软化,使得奖励函数变得可微,从而可以利用梯度下降等优化算法来优化策略。
技术框架:该框架主要包含以下几个模块:1) LTL规范解析器:将LTL规范转换为Büchi自动机。2) 可微仿真环境:提供可微的状态转移函数和奖励函数。3) 软标签模块:将离散的自动机状态转换为连续的软标签,使得状态转移变得可微。4) 强化学习算法:利用可微的奖励函数和状态表示来训练策略。整体流程是:首先将LTL规范转换为Büchi自动机,然后利用软标签模块将自动机状态转换为连续表示,接着在可微仿真环境中进行强化学习训练,最后得到满足LTL规范的控制策略。
关键创新:该论文最重要的创新点在于将LTL规范与可微仿真环境相结合,通过软标签的方式将离散的自动机状态转换为连续表示,从而使得奖励函数变得可微。这种方法可以有效地缓解LTL奖励的稀疏性问题,并能够利用梯度信息来加速强化学习的训练过程。这是首次将LTL与可微仿真结合,实现端到端的形式化规范驱动的强化学习。
关键设计:论文的关键设计包括:1) 使用软标签来表示自动机状态,具体来说,使用sigmoid函数来对状态进行软化,从而使得状态转移变得可微。2) 设计了可微的奖励函数,该奖励函数基于软标签的状态转移概率来计算,从而能够反映LTL规范的满足程度。3) 理论上推导了Büchi接受与离散和可微LTL回报之间的关系,并给出了差异的可调边界。4) 实验中使用了TRPO等强化学习算法,并针对具体任务进行了参数调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在复杂的、非线性的、富含接触的连续控制任务中,显著加速了训练,并实现了高达两倍于离散基线的收益。例如,在某个具体的连续控制任务中,使用该方法训练的智能体能够更快地学会满足LTL规范,并且最终的性能指标比使用离散LTL奖励的智能体高出100%。此外,该方法还展示了与奖励机器的兼容性,从而无需修改即可覆盖co-safe LTL和LTL$_ ext{f}$。
🎯 应用场景
该研究成果可应用于机器人、自动驾驶、智能制造等领域,在这些领域中,安全性和可靠性至关重要。通过将形式化规范与强化学习相结合,可以确保智能体在复杂环境中安全可靠地运行,并满足预定义的规范要求。该方法还可以用于验证和调试控制系统,提高系统的安全性和可靠性。
📄 摘要(原文)
Ensuring that reinforcement learning (RL) controllers satisfy safety and reliability constraints in real-world settings remains challenging: state-avoidance and constrained Markov decision processes often fail to capture trajectory-level requirements or induce overly conservative behavior. Formal specification languages such as linear temporal logic (LTL) offer correct-by-construction objectives, yet their rewards are typically sparse, and heuristic shaping can undermine correctness. We introduce, to our knowledge, the first end-to-end framework that integrates LTL with differentiable simulators, enabling efficient gradient-based learning directly from formal specifications. Our method relaxes discrete automaton transitions via soft labeling of states, yielding differentiable rewards and state representations that mitigate the sparsity issue intrinsic to LTL while preserving objective soundness. We provide theoretical guarantees connecting Büchi acceptance to both discrete and differentiable LTL returns and derive a tunable bound on their discrepancy in deterministic and stochastic settings. Empirically, across complex, nonlinear, contact-rich continuous-control tasks, our approach substantially accelerates training and achieves up to twice the returns of discrete baselines. We further demonstrate compatibility with reward machines, thereby covering co-safe LTL and LTL$_\text{f}$ without modification. By rendering automaton-based rewards differentiable, our work bridges formal methods and deep RL, enabling safe, specification-driven learning in continuous domains.