Convergence of Byzantine-Resilient Gradient Tracking via Probabilistic Edge Dropout
作者: Amirhossein Dezhboro, Fateme Maleki, Arman Adibi, Erfan Amini, Jose E. Ramirez-Marquez
分类: cs.LG, cs.MA, eess.SY
发布日期: 2026-04-01
💡 一句话要点
提出基于概率边丢弃的拜占庭容错梯度追踪方法,解决分布式优化中的恶意攻击问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 分布式优化 拜占庭容错 梯度追踪 概率边丢弃 联邦学习
📋 核心要点
- 现有分布式优化方法在拜占庭攻击下鲁棒性不足,易受恶意节点发送的任意消息干扰。
- 提出GT-PD方法,通过自中心投影和概率边丢弃,限制对抗扰动并保持双重随机混合结构。
- 实验表明,GT-PD-L在MNIST数据集上,针对多种攻击,优于坐标式修剪均值。
📝 摘要(中文)
本文研究了存在拜占庭代理的网络上的分布式优化问题,这些代理可能会发送任意对抗性消息。我们提出了一种具有概率边丢弃的梯度追踪方法(GT-PD),这是一种随机梯度追踪方法,可在对抗性通信下保持梯度追踪的收敛性。GT-PD结合了两个互补的防御层:一种通用的自中心投影,将每个传入消息裁剪到接收代理周围半径为τ的球内;以及一种完全分散的概率丢弃规则,该规则由决策和跟踪通道中的双度量信任分数驱动。这种设计限制了对抗性扰动,同时保留了双重随机混合结构,这是在分散设置中鲁棒聚合下经常丢失的属性。在完全拜占庭隔离($p_b=0$)下,GT-PD线性收敛到仅由随机梯度方差决定的邻域。对于部分隔离($p_b>0$),我们引入了具有概率边丢弃和泄漏积分的梯度追踪(GT-PD-L),它使用泄漏积分器来控制由持续扰动引起的跟踪误差的累积,并实现线性收敛到由随机方差和裁剪-泄漏比率决定的有界邻域。我们进一步表明,在$p_h=1$的双层丢弃下,隔离拜占庭代理不会给诚实验共识动态带来额外的方差。在Sign Flip、ALIE和Inner Product Manipulation攻击下,MNIST上的实验表明,在隐蔽攻击下,GT-PD-L的性能优于坐标式修剪均值高达4.3个百分点。
🔬 方法详解
问题定义:在分布式优化中,拜占庭攻击是指网络中的恶意节点(拜占庭节点)发送任意的、可能具有误导性的信息,从而干扰整个网络的优化过程。现有的分布式优化方法,特别是梯度追踪算法,在面对这种攻击时,鲁棒性较差,容易受到恶意节点的影响,导致算法收敛速度下降甚至发散。因此,如何设计一种能够抵抗拜占庭攻击的分布式优化算法是一个重要的研究问题。
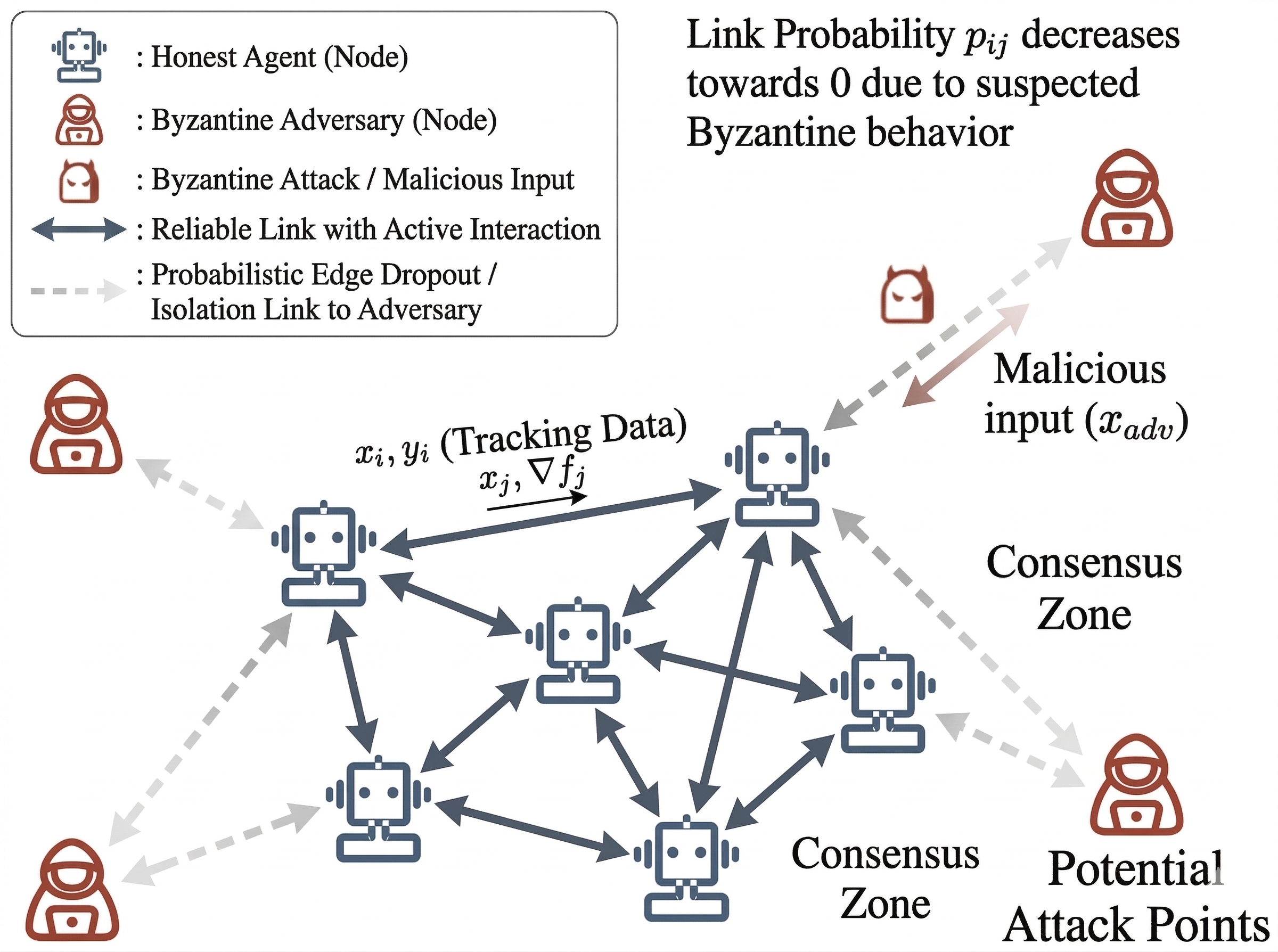
核心思路:本文的核心思路是通过结合自中心投影和概率边丢弃两种防御机制,来限制拜占庭节点的影响,并保持算法的收敛性。自中心投影通过将接收到的消息裁剪到接收代理周围的一个球内,限制了恶意节点发送的过大或不合理的信息。概率边丢弃则根据一个双度量信任分数,随机地丢弃一些来自其他节点的信息,从而降低恶意节点的影响。
技术框架:GT-PD算法的整体框架如下:每个节点维护一个本地的梯度估计和一个本地的变量。在每次迭代中,每个节点首先计算本地的梯度,然后与其他节点交换梯度信息。接收到其他节点的梯度信息后,每个节点首先使用自中心投影对接收到的信息进行裁剪,然后根据概率边丢弃规则,随机地丢弃一些信息。最后,每个节点使用剩余的信息更新本地的梯度估计和变量。对于部分隔离的情况,引入GT-PD-L算法,使用泄漏积分器来控制跟踪误差的累积。
关键创新:本文的关键创新在于将自中心投影和概率边丢弃两种防御机制结合起来,并设计了一个双度量信任分数来驱动概率边丢弃。这种设计既限制了恶意节点的影响,又保持了算法的双重随机混合结构,从而保证了算法的收敛性。此外,GT-PD-L算法通过引入泄漏积分器,进一步提高了算法在部分隔离情况下的鲁棒性。
关键设计:GT-PD算法的关键设计包括:1) 自中心投影的半径τ的选择,需要根据具体的应用场景进行调整,以平衡对恶意节点的限制和对有用信息的保留。2) 双度量信任分数的设计,需要综合考虑节点的历史行为和当前行为,以准确地评估节点的可靠性。3) 概率边丢弃的概率,需要根据网络中的恶意节点比例进行调整,以平衡对恶意节点的抑制和对网络连通性的保持。4) GT-PD-L算法中泄漏积分器的泄漏率,需要根据具体的应用场景进行调整,以平衡对跟踪误差的抑制和对有用信息的利用。
🖼️ 关键图片


📊 实验亮点
在MNIST数据集上,针对Sign Flip、ALIE和Inner Product Manipulation等多种攻击,GT-PD-L算法的性能优于坐标式修剪均值高达4.3个百分点。该实验结果表明,GT-PD-L算法在抵抗拜占庭攻击方面具有显著的优势,能够有效地提高分布式优化算法的鲁棒性。
🎯 应用场景
该研究成果可应用于联邦学习、分布式机器人、传感器网络等领域,在这些场景中,节点可能受到恶意攻击或发生故障。通过使用该方法,可以提高分布式系统的鲁棒性和可靠性,保证系统在恶意环境下的正常运行。未来,该方法可以进一步扩展到更复杂的网络拓扑和更广泛的攻击模型。
📄 摘要(原文)
We study distributed optimization over networks with Byzantine agents that may send arbitrary adversarial messages. We propose \emph{Gradient Tracking with Probabilistic Edge Dropout} (GT-PD), a stochastic gradient tracking method that preserves the convergence properties of gradient tracking under adversarial communication. GT-PD combines two complementary defense layers: a universal self-centered projection that clips each incoming message to a ball of radius $τ$ around the receiving agent, and a fully decentralized probabilistic dropout rule driven by a dual-metric trust score in the decision and tracking channels. This design bounds adversarial perturbations while preserving the doubly stochastic mixing structure, a property often lost under robust aggregation in decentralized settings. Under complete Byzantine isolation ($p_b=0$), GT-PD converges linearly to a neighborhood determined solely by stochastic gradient variance. For partial isolation ($p_b>0$), we introduce \emph{Gradient Tracking with Probabilistic Edge Dropout and Leaky Integration} (GT-PD-L), which uses a leaky integrator to control the accumulation of tracking errors caused by persistent perturbations and achieves linear convergence to a bounded neighborhood determined by the stochastic variance and the clipping-to-leak ratio. We further show that under two-tier dropout with $p_h=1$, isolating Byzantine agents introduces no additional variance into the honest consensus dynamics. Experiments on MNIST under Sign Flip, ALIE, and Inner Product Manipulation attacks show that GT-PD-L outperforms coordinate-wise trimmed mean by up to 4.3 percentage points under stealth attacks.