A Novel Hybrid Heuristic-Reinforcement Learning Optimization Approach for a Class of Railcar Shunting Problems
作者: Ruonan Zhao, Joseph Geunes
分类: cs.LG, math.OC
发布日期: 2026-03-05
💡 一句话要点
提出混合启发式-强化学习算法,解决铁路货场调车场优化问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 铁路调车 组合优化 启发式算法 强化学习 Q-learning
📋 核心要点
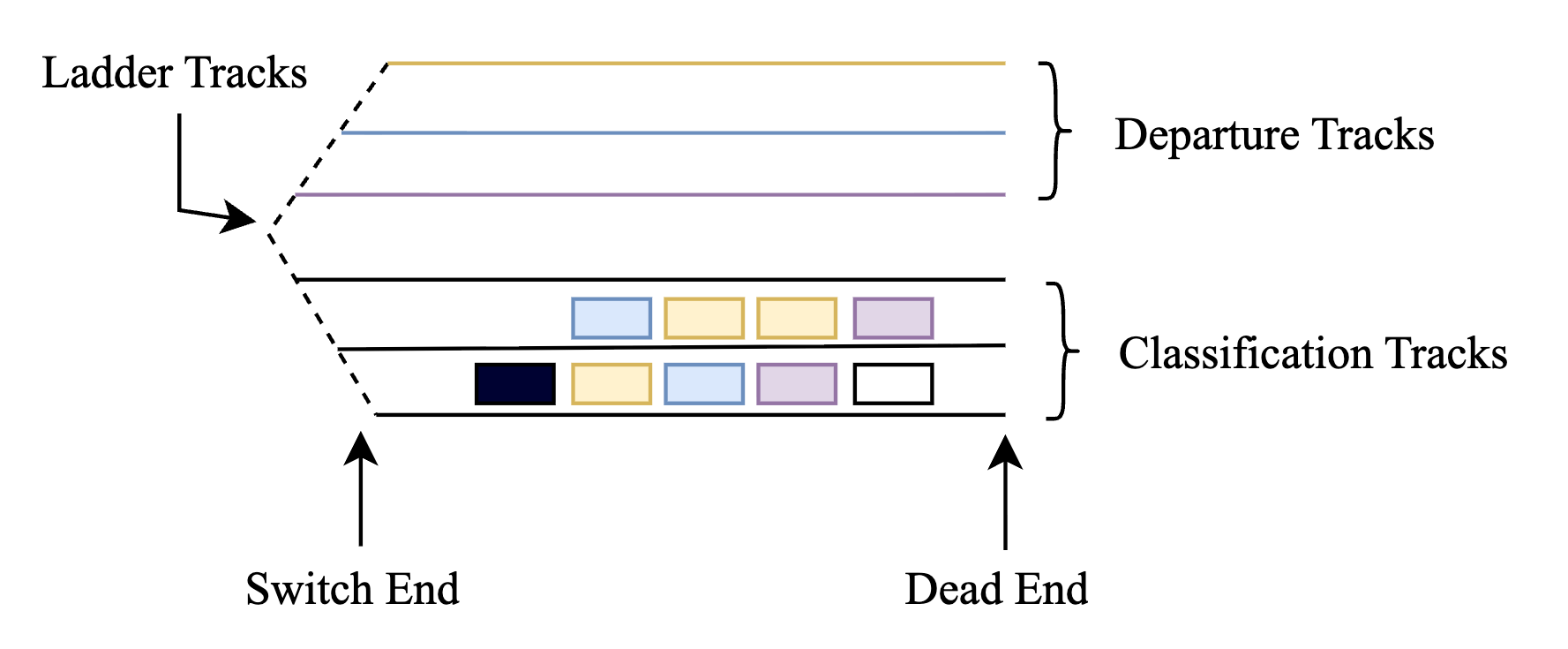
- 铁路货场调车问题具有高度的组合复杂性,传统方法难以在合理时间内找到最优解。
- 论文提出混合启发式-强化学习(HHRL)框架,结合启发式算法的快速性和强化学习的自适应性。
- 实验结果表明,HHRL算法在单侧和双侧轨道进路问题中均表现出高效性和高质量的解决方案。
📝 摘要(中文)
铁路货场调车是货运铁路的核心规划任务,需要对车厢进行解编和重组以形成出站列车。单侧进路的分类轨道可以视为堆栈结构,车厢只能在一端添加和移除,导致后进先出(LIFO)的检索顺序。相比之下,双侧轨道的功能类似于队列结构,允许从一端添加车厢,从另一端移除车厢,遵循先进先出(FIFO)的顺序。本文考虑了一个问题,即使用两台机车在具有双侧分类轨道进路的货场中组装多个出站列车。为了解决这个组合优化难题,我们将问题分解为两个子问题,每个子问题都具有单侧分类轨道进路和一台机车。我们提出了一种新颖的混合启发式-强化学习(HHRL)框架,该框架将铁路特定的启发式解决方案与强化学习方法(特别是Q-learning)相结合。所提出的框架利用方法来减少状态-动作空间,并指导强化学习期间的探索。一系列数值实验的结果证明了HHRL算法在单侧进路、单机车问题和双侧进路、双机车问题中的效率和质量。
🔬 方法详解
问题定义:论文旨在解决铁路货场中多列出站列车的编组问题,该问题涉及如何有效地利用分类轨道(单侧和双侧)和机车来解编和重组车厢。现有方法,如传统优化算法,在面对大规模和复杂的调车场景时,计算复杂度高,难以在合理时间内找到最优解。启发式算法虽然速度快,但可能陷入局部最优。
核心思路:论文的核心思路是将启发式算法和强化学习相结合,利用启发式算法快速生成初始解,并利用强化学习算法在启发式解的基础上进行优化。这种混合方法旨在结合两者的优点,既能保证求解速度,又能提高解的质量。
技术框架:HHRL框架包含以下主要模块:1) 问题分解:将原始问题分解为两个子问题,每个子问题对应一个单侧轨道进路和一个机车。2) 启发式算法:使用铁路特定的启发式算法为每个子问题生成初始解。3) 强化学习:使用Q-learning算法在启发式解的基础上进行优化。4) 状态-动作空间缩减:采用方法来减少状态-动作空间,提高强化学习的效率。
关键创新:该方法最重要的创新点在于将启发式算法和强化学习有机结合,并针对铁路调车问题的特点,设计了状态-动作空间缩减方法。与传统的纯启发式或纯强化学习方法相比,HHRL框架能够更好地平衡求解速度和解的质量。
关键设计:在Q-learning算法中,状态空间包括车厢在轨道上的分布、机车的位置等信息。动作空间包括移动车厢、切换轨道等操作。奖励函数的设计旨在鼓励算法找到能够快速完成列车编组的策略。此外,论文还设计了启发式规则来指导强化学习的探索过程,避免算法陷入局部最优。
🖼️ 关键图片


📊 实验亮点
数值实验结果表明,HHRL算法在单侧和双侧轨道进路问题中均表现出良好的性能。与传统的启发式算法相比,HHRL算法能够找到质量更高的解。此外,通过状态-动作空间缩减,HHRL算法的求解速度也得到了显著提升。具体性能数据(例如,解的平均质量提升百分比、求解时间缩短百分比)未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于铁路货运的智能调度系统,提高货场作业效率,降低运营成本。通过优化列车编组计划,可以减少车厢的移动次数和等待时间,从而提高整个铁路运输系统的效率。此外,该方法还可以推广到其他类似的物流和生产调度问题。
📄 摘要(原文)
Railcar shunting is a core planning task in freight railyards, where yard planners need to disassemble and reassemble groups of railcars to form outbound trains. Classification tracks with access from one side only can be considered as stack structures, where railcars are added and removed from only one end, leading to a last-in-first-out (LIFO) retrieval order. In contrast, two-sided tracks function like queue structures, allowing railcars to be added from one end and removed from the opposite end, following a first-in-first-out (FIFO) order. We consider a problem requiring assembly of multiple outbound trains using two locomotives in a railyard with two-sided classification track access. To address this combinatorially challenging problem class, we decompose the problem into two subproblems, each with one-sided classification track access and a locomotive on each side. We present a novel Hybrid Heuristic-Reinforcement Learning (HHRL) framework that integrates railway-specific heuristic solution approaches with a reinforcement learning method, specifically Q-learning. The proposed framework leverages methods to decrease the state-action space and guide exploration during reinforcement learning. The results of a series of numerical experiments demonstrate the efficiency and quality of the HHRL algorithm in both one-sided access, single-locomotive problems and two-sided access, two-locomotive problems.