ShareVerse: Multi-Agent Consistent Video Generation for Shared World Modeling
作者: Jiayi Zhu, Jianing Zhang, Yiying Yang, Wei Cheng, Xiaoyun Yuan
分类: cs.CV, cs.AI
发布日期: 2026-03-03
💡 一句话要点
ShareVerse:提出多智能体一致性视频生成框架,用于共享世界建模
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 多智能体 视频生成 共享世界建模 跨智能体注意力 CARLA
📋 核心要点
- 现有视频生成方法缺乏对多智能体交互场景下统一共享世界建模的支持,难以保证多智能体视角下场景的一致性。
- ShareVerse通过空间拼接多智能体视角视频,并引入跨智能体注意力机制,实现时空信息交互,保证共享世界的一致性。
- ShareVerse在CARLA数据集上实现了49帧大规模视频生成,能够准确感知动态智能体的位置,并实现一致的共享世界建模。
📝 摘要(中文)
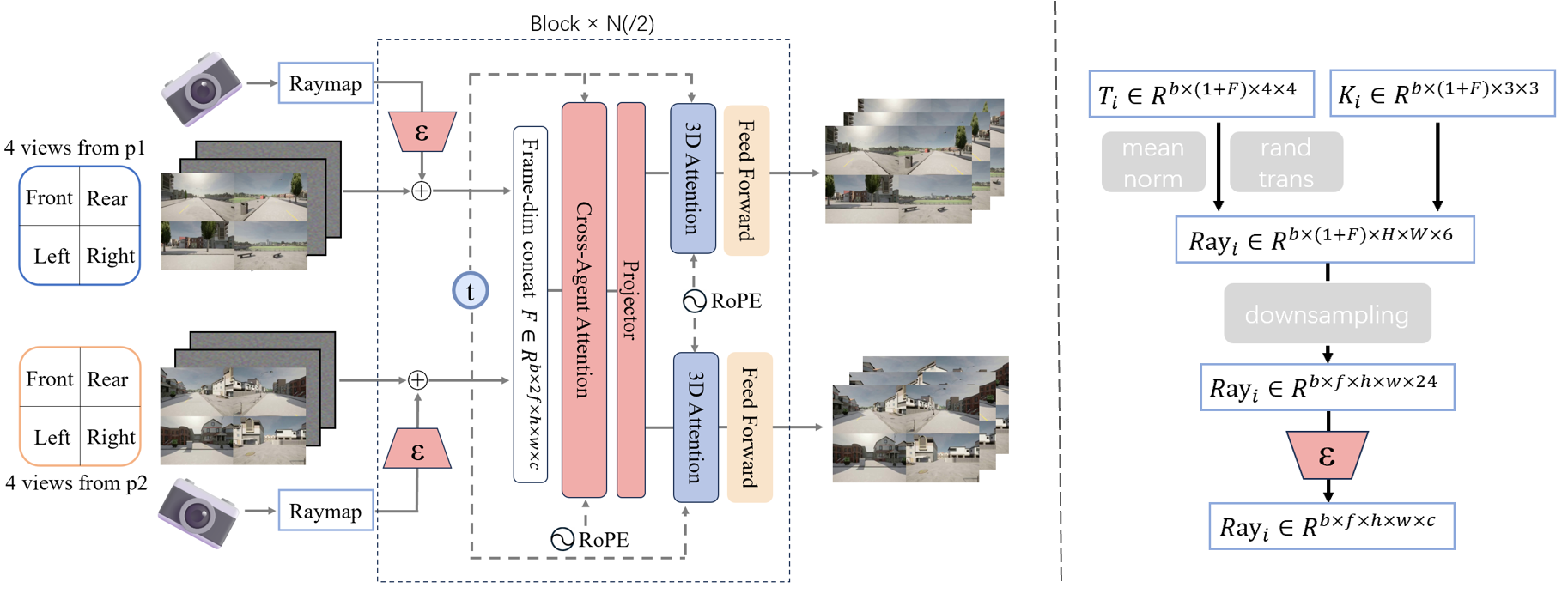
本文提出了ShareVerse,一个支持多智能体共享世界建模的视频生成框架,旨在弥补现有工作在构建具有多智能体交互的统一共享世界方面的不足。ShareVerse利用大型视频模型的生成能力,并整合了三个关键创新:1) 在CARLA模拟平台上构建了一个大规模多智能体交互世界建模数据集,该数据集具有多样化的场景、天气条件和交互轨迹,并配有多视角视频(每个智能体的前/后/左/右视图)和相机数据。2) 我们提出了一种空间拼接策略,用于独立智能体的四视图视频,以建模更广阔的环境并确保内部多视图几何一致性。3) 我们将跨智能体注意力模块集成到预训练的视频模型中,从而实现跨智能体的时空信息交互传输,保证重叠区域的共享世界一致性以及非重叠区域的合理生成。ShareVerse支持49帧的大规模视频生成,能够准确感知动态智能体的位置,并实现一致的共享世界建模。
🔬 方法详解
问题定义:现有视频生成方法难以处理多智能体交互场景下的共享世界建模问题。具体来说,不同智能体视角下的场景信息如何融合,如何保证生成视频在不同视角下的一致性,以及如何处理非重叠区域的合理生成,都是现有方法的痛点。
核心思路:ShareVerse的核心思路是利用多智能体视角信息,通过空间拼接和跨智能体注意力机制,实现对共享世界的统一建模。通过空间拼接,将不同智能体的视角信息整合到一起,从而扩大视野范围。通过跨智能体注意力机制,实现不同智能体之间的信息交互,从而保证生成视频在不同视角下的一致性。
技术框架:ShareVerse的整体框架包括数据准备、空间拼接和视频生成三个主要阶段。首先,在CARLA模拟平台上构建大规模多智能体交互数据集,包含多视角视频和相机数据。然后,采用空间拼接策略,将不同智能体的四视图视频拼接在一起,形成更广阔的场景表示。最后,将拼接后的视频输入到预训练的视频模型中,并集成跨智能体注意力模块,生成一致的共享世界视频。
关键创新:ShareVerse的关键创新在于提出了空间拼接策略和跨智能体注意力机制。空间拼接策略能够有效地整合多智能体视角信息,扩大视野范围。跨智能体注意力机制能够实现不同智能体之间的信息交互,保证生成视频在不同视角下的一致性。与现有方法相比,ShareVerse能够更好地处理多智能体交互场景下的共享世界建模问题。
关键设计:在空间拼接方面,采用了简单的空间拼接方式,将四个视角的视频按照一定的顺序拼接在一起。在跨智能体注意力机制方面,将注意力模块集成到预训练的视频模型中,允许不同智能体之间的信息进行交互。具体的网络结构和参数设置未知,论文中可能没有详细描述。
🖼️ 关键图片


📊 实验亮点
ShareVerse在CARLA数据集上进行了实验,结果表明,ShareVerse能够准确感知动态智能体的位置,并生成一致的共享世界视频。ShareVerse支持49帧的大规模视频生成,相较于现有方法,在多智能体交互场景下的视频生成质量有了显著提升。具体的性能数据和提升幅度未知,论文中可能没有给出详细的量化指标。
🎯 应用场景
ShareVerse的研究成果可应用于自动驾驶、机器人协同、虚拟现实等领域。例如,在自动驾驶中,可以利用ShareVerse生成多车辆视角下的场景视频,提高自动驾驶系统的感知能力和决策能力。在机器人协同中,可以利用ShareVerse模拟多机器人协同作业场景,提高机器人协同效率。在虚拟现实中,可以利用ShareVerse生成多用户共享的虚拟环境,增强用户体验。
📄 摘要(原文)
This paper presents ShareVerse, a video generation framework enabling multi-agent shared world modeling, addressing the gap in existing works that lack support for unified shared world construction with multi-agent interaction. ShareVerse leverages the generation capability of large video models and integrates three key innovations: 1) A dataset for large-scale multi-agent interactive world modeling is built on the CARLA simulation platform, featuring diverse scenes, weather conditions, and interactive trajectories with paired multi-view videos (front/ rear/ left/ right views per agent) and camera data. 2) We propose a spatial concatenation strategy for four-view videos of independent agents to model a broader environment and to ensure internal multi-view geometric consistency. 3) We integrate cross-agent attention blocks into the pretrained video model, which enable interactive transmission of spatial-temporal information across agents, guaranteeing shared world consistency in overlapping regions and reasonable generation in non-overlapping regions. ShareVerse, which supports 49-frame large-scale video generation, accurately perceives the position of dynamic agents and achieves consistent shared world modeling.