ProtRLSearch: A Multi-Round Multimodal Protein Search Agent with Large Language Models Trained via Reinforcement Learning
作者: Congying Liu, Taihao Li, Ming Huang, Xingyuan Wei, Peipei Liu, Yiqing Shen, Yanxu Mao, Tiehan Cui
分类: cs.AI, cs.CL
发布日期: 2026-03-02
💡 一句话要点
ProtRLSearch:提出一种基于强化学习的多轮多模态蛋白质搜索Agent,用于解决蛋白质分析任务。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 蛋白质搜索 强化学习 多模态融合 蛋白质序列 自然语言处理
📋 核心要点
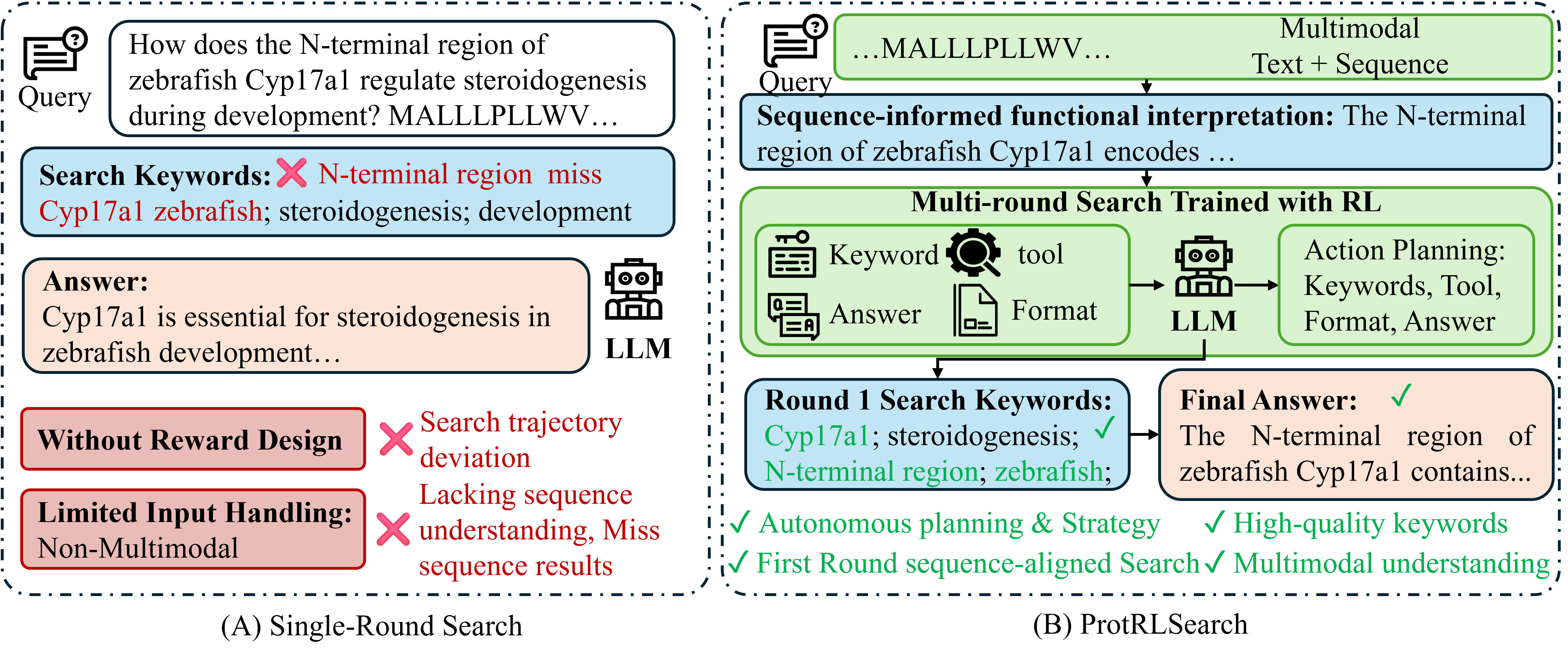
- 现有蛋白质搜索Agent主要局限于单轮、纯文本模态搜索,无法有效整合蛋白质序列信息。
- ProtRLSearch利用多维奖励强化学习训练,实现多轮搜索,并融合蛋白质序列和文本信息作为多模态输入。
- 构建了ProtMCQs基准数据集,包含3000道多项选择题,用于评估模型在不同难度下的蛋白质查询能力。
📝 摘要(中文)
本文提出ProtRLSearch,一种基于多维奖励强化学习训练的多轮蛋白质搜索Agent,它在实时搜索过程中联合利用蛋白质序列和文本作为多模态输入,以生成高质量的报告。为了评估模型在实际蛋白质查询环境中整合蛋白质序列信息和基于文本的多模态输入的能力,作者构建了ProtMCQs,一个包含3000道多项选择题(MCQ)的基准数据集,分为三个难度级别。该基准评估了蛋白质查询任务,范围从关于蛋白质功能和表型变化的序列约束推理,到整合多维序列特征与信号通路和调控网络的综合蛋白质推理。
🔬 方法详解
问题定义:蛋白质分析任务,如疾病相关变异的功能解释和临床研究的蛋白质水平分析,需要在蛋白质序列约束下进行精确推理。现有的蛋白质搜索Agent主要存在两个痛点:一是仅支持单轮、纯文本模态搜索,无法有效利用蛋白质序列信息;二是依赖于仅关注最终答案的强化学习监督,缺乏搜索过程约束,难以纠正关键词选择和推理方向的偏差。
核心思路:ProtRLSearch的核心思路是构建一个多轮搜索Agent,通过强化学习训练,使其能够同时利用蛋白质序列和文本信息进行搜索决策。通过多轮搜索,Agent可以逐步完善搜索策略,并生成更准确的报告。通过多模态输入,Agent可以更全面地理解蛋白质相关信息。
技术框架:ProtRLSearch的整体框架包含以下几个主要模块:1) 多模态输入模块:接收蛋白质序列和文本信息作为输入;2) 搜索Agent:基于强化学习策略,选择搜索关键词并执行搜索;3) 知识库:存储蛋白质相关信息,如序列、功能、结构等;4) 奖励函数:根据搜索结果的质量,为Agent提供奖励信号;5) 报告生成模块:根据搜索结果,生成最终的蛋白质分析报告。
关键创新:ProtRLSearch的关键创新在于:1) 提出了多模态蛋白质搜索Agent,能够同时利用蛋白质序列和文本信息;2) 采用了多维奖励强化学习,对搜索过程进行更细粒度的约束;3) 构建了ProtMCQs基准数据集,用于评估模型在实际蛋白质查询环境中的性能。
关键设计:具体的技术细节包括:1) 使用Transformer模型对蛋白质序列和文本信息进行编码;2) 设计了多维奖励函数,包括准确率奖励、相关性奖励和多样性奖励;3) 使用了Actor-Critic算法进行强化学习训练;4) ProtMCQs数据集包含三个难度级别,分别评估模型的序列约束推理、蛋白质功能推理和综合蛋白质推理能力。
🖼️ 关键图片


📊 实验亮点
论文构建了ProtMCQs基准数据集,并在该数据集上评估了ProtRLSearch的性能。实验结果表明,ProtRLSearch能够有效整合蛋白质序列和文本信息,并在不同难度级别的蛋白质查询任务中取得显著的性能提升。相较于基线模型,ProtRLSearch在准确率和召回率方面均有明显改善。
🎯 应用场景
ProtRLSearch具有广泛的应用前景,可用于疾病相关变异的功能解释、蛋白质功能预测、药物靶点发现等领域。该研究有助于提高蛋白质分析的准确性和效率,为生物医学研究和临床应用提供有力支持,并加速新药研发进程。
📄 摘要(原文)
Protein analysis tasks arising in healthcare settings often require accurate reasoning under protein sequence constraints, involving tasks such as functional interpretation of disease-related variants, protein-level analysis for clinical research, and similar scenarios. To address such tasks, search agents are introduced to search protein-related information, providing support for disease-related variant analysis and protein function reasoning in protein-centric inference. However, such search agents are mostly limited to single-round, text-only modality search, which prevents the protein sequence modality from being incorporated as a multimodal input into the search decision-making process. Meanwhile, their reliance on reinforcement learning (RL) supervision that focuses solely on the final answer results in a lack of search process constraints, making deviations in keyword selection and reasoning directions difficult to identify and correct in a timely manner. To address these limitations, we propose ProtRLSearch, a multi-round protein search agent trained with multi-dimensional reward based RL, which jointly leverages protein sequence and text as multimodal inputs during real-time search to produce high quality reports. To evaluate the ability of models to integrate protein sequence information and text-based multimodal inputs in realistic protein query settings, we construct ProtMCQs, a benchmark of 3,000 multiple choice questions (MCQs) organized into three difficulty levels. The benchmark evaluates protein query tasks that range from sequence constrained reasoning about protein function and phenotype changes to comprehensive protein reasoning that integrates multi-dimensional sequence features with signal pathways and regulatory networks.